
What Does It Mean to Move an AI Agent Pilot to Production?
The board approved the budget, your teams launched dozens of agent pilots, and almost none reached production. That gap is now the central question for any CIO or Chief AI Officer, because moving an AI agent pilot to production is where reliability, ownership, and operational control decide everything. An AI agent is a software system that perceives context, decides on actions, and executes multi-step tasks toward a goal, and agentic AI refers to the broader class of these goal-directed systems. A pilot is a demo that proves the agent can do a task once under watch. Production is the agent running on real work, unattended, with the business depending on the result. The distance between those two states is not about model quality. It is about engineering.
MIT found that 95% of enterprise generative AI pilots deliver no measurable P and L impact, with only about 5% extracting significant value. That research, based on 150 leader interviews, a survey of 350 employees, and 300 public deployments, is explicit that the root cause is not the model. It is the learning gap: the work of integrating AI into workflows, structures, and culture. Forrester narrows the same story to agents, describing most enterprises as stuck in proof-of-concept purgatory, where pilots never cross into production. The blockers Forrester names are orchestration, control, and trust.
MIT, The GenAI Divide, 2025: 95% of enterprise generative AI pilots deliver no measurable ROI. The cited root cause is the integration learning gap, not weak models.
Why Do So Many AI Agent Pilots Stall at the Last Mile?
A pilot is graded on a good demo. Production is graded on what happens at 2 a.m. when an input arrives that nobody scripted. Orchestration, the coordination of an agent across tools, data, and steps, holds up in a controlled demo and breaks under real traffic. Trust erodes the first time a confident agent is confidently wrong with no record of why. Gartner predicts that over 40% of agentic AI projects will be canceled by the end of 2027, citing weak governance, unclear value, and escalating costs. Those are not model failures. They are the absence of the production engineering that a demo never needed.
The same MIT research points to the fix. Pilots that blended internal teams with external expertise reached a 67% success rate, against 22% for builds owned by IT alone. The agents that cross the gap are the ones engineered for the gap, not the ones with the cleverest demo.
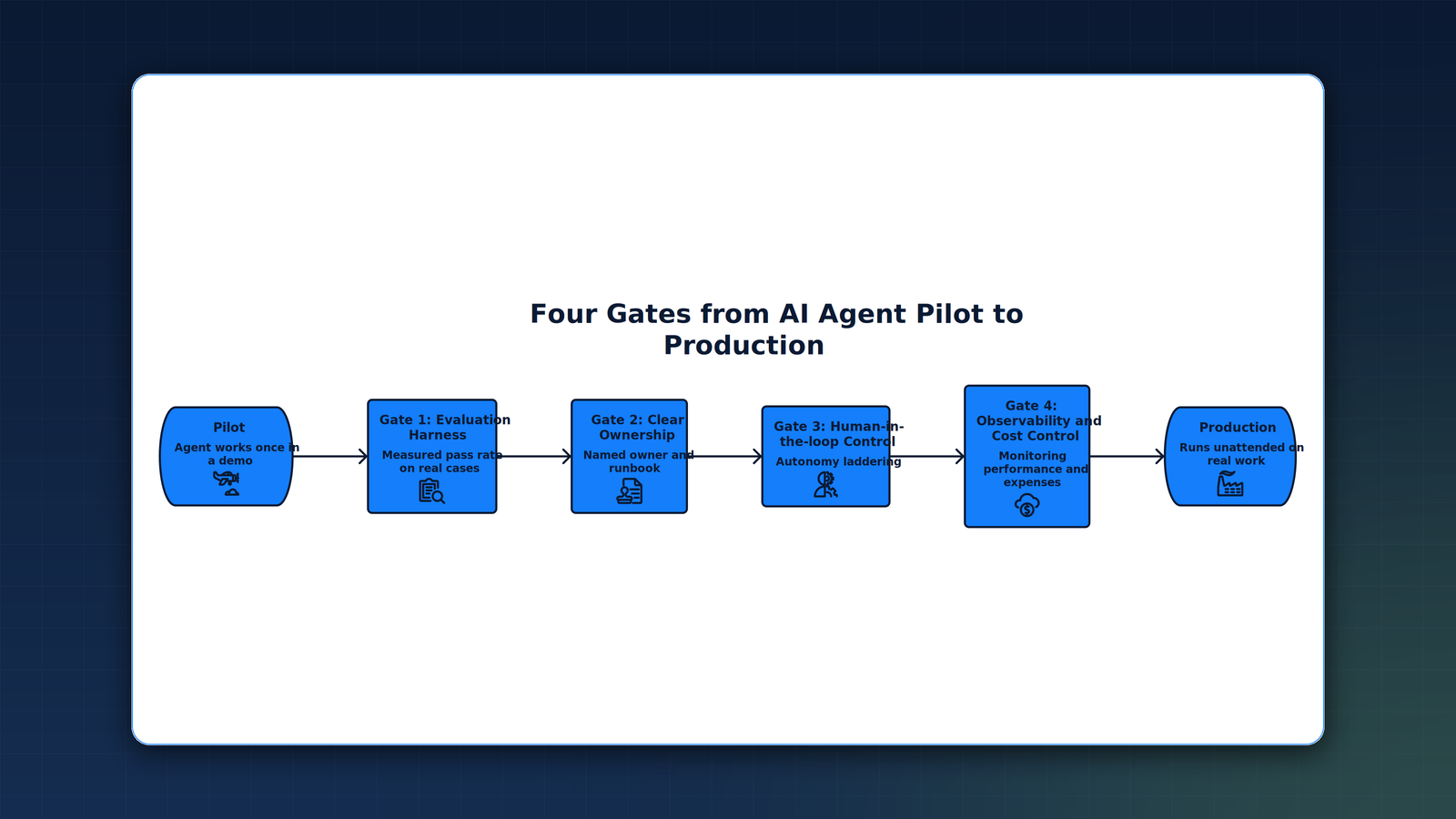
The Four Gates: A Production Framework for AI Agent Pilot to Production
Treat the move from demo to dependable system as four gates. An agent does not advance until it clears each one. Every gate is concrete and measurable, so the question is never whether the agent demoed well, but whether it passed.
- Evaluation harness. An evaluation harness, often shortened to eval, is a repeatable test suite that scores the agent against real historical cases before anyone trusts it in production. Instead of it demoed well, you get a measured pass rate on the work the business actually sees. If the agent cannot clear a defined threshold on last quarter of real cases, it does not ship. The harness then becomes the regression gate for every future change.
- Clear ownership. A production agent has a named owner and a runbook that states what it does, what it must never do, and what to do when it breaks. This turns the agent from an orphaned demo into an operated system. Without an owner, no one is accountable for the pass rate, the cost, or the 2 a.m. failure, and the pilot quietly dies.
- Human-in-the-loop control. Human-in-the-loop means a person reviews or approves the agent actions at defined points rather than after the fact. You set this through autonomy laddering, the practice of granting autonomy in graded levels with explicit approval gates. The agent acts freely inside its bounds, requires sign-off at higher-stakes steps, and escalates exceptions instead of guessing. Autonomy is earned as the measured pass rate justifies it.
- Observability and cost control. Observability is the ability to see what the agent did and why from its logs and traces. Production agents need logging of every decision, drift monitoring to catch quality decay as inputs change, and run-rate and token tracking so spend stays visible. This is the gate that prevents the escalating costs and silent failures behind the cancellations Gartner forecasts.
The gates are sequential in trust but continuous in operation. The eval is what lets you raise the autonomy ladder safely. Ownership is what keeps observability acted upon rather than merely collected. Skip one and the others weaken.
How Do You Know an Agent Is Actually Ready for Production?
Readiness is not a feeling, it is evidence. The agent clears a documented pass rate on real historical cases. It has a named owner and a runbook. Its autonomy level is explicit and matched to its measured reliability. Its logs, drift signals, and run-rate are visible on a dashboard someone watches. When all four hold, the demo has become a system the business can depend on. When any one is missing, you have a pilot wearing a production label, which is exactly the state MIT, Forrester, and Gartner are all measuring.
Key Takeaways
- The pilot-to-production gap is an engineering problem, not a model problem. MIT attributes the 95% generative AI pilot failure rate to the integration learning gap.
- Forrester finds most agentic AI stuck in proof-of-concept purgatory, blocked by orchestration, control, and trust, not by model capability.
- Four gates carry an agent across: an evaluation harness, clear ownership, human-in-the-loop control via autonomy laddering, and observability with cost control.
- Each gate is measurable. The eval replaces it demoed well with a pass rate, and the autonomy ladder is raised only as that rate justifies it.
- Blending internal teams with external expertise reached a 67% success rate in MIT data, versus 22% for IT-only builds.
What is the difference between an AI agent pilot and production?
A pilot proves the agent can do a task once, under supervision, in controlled conditions. Production is the agent running on real work unattended, with the business depending on the output. The four gates exist to close that distance with evidence rather than optimism.
Is the 95% failure figure specific to AI agents?
No. The MIT 95% figure covers enterprise generative AI pilots broadly, not agents specifically. The agent-specific picture comes from Forrester, which finds most agentic AI stuck in pilots, and from Gartner, which forecasts over 40% of agentic AI projects canceled by end of 2027.
Which gate should we build first?
The evaluation harness. Without a measured pass rate on real cases, you cannot judge whether the agent is improving, cannot set a defensible autonomy level, and cannot tell whether a change helped or hurt. The eval is the foundation the other three gates rest on.
Sources
- MIT NANDA, "The GenAI Divide: State of AI in Business 2025," 2025. Link.
- Forrester, "The State of Agentic AI in 2026: Companies Are Chasing, Few Are Catching," 2026. Link.
- Gartner, "Gartner Predicts Over 40% of Agentic AI Projects Will Be Canceled by End of 2027," 2025. Link.
Next Steps
The decision in front of you is which pilots deserve the engineering to reach production and which should be retired. Stable Solutions is an MIT-trained R and D partner that builds the evaluation harnesses, human-in-the-loop controls, and observability that carry an agent across the pilot-to-production gap, not another pilot to add to the pile. Review the governance side of this in our guide to AI governance and guardrails at scale, explore our AI Automation work or how we serve AI and automation teams, and contact our team to decide which agents are worth carrying to production.