
Where does the model actually run, and why is that the real decision?
For most enterprise mobile teams, the question is no longer whether to add intelligence to the product. Gartner predicts that 40% of enterprise apps will feature task-specific AI agents by 2026, up from less than 5% in 2025. The harder call sits one layer down, at the architecture. It is a question of where inference (running a trained model to produce a result) happens: on-device AI mobile architecture, meaning the model runs on the phone itself; in the cloud, meaning it runs in a data center the app calls over the network; or split across the two. That placement decides the latency (the delay between a request and a response) a user feels, the regulatory exposure the company carries, and the run-rate (the recurring monthly cost to operate) finance signs off on. Get it wrong and the fix is a re-platform (a ground-up rebuild of the architecture, not a config change), not a patch.
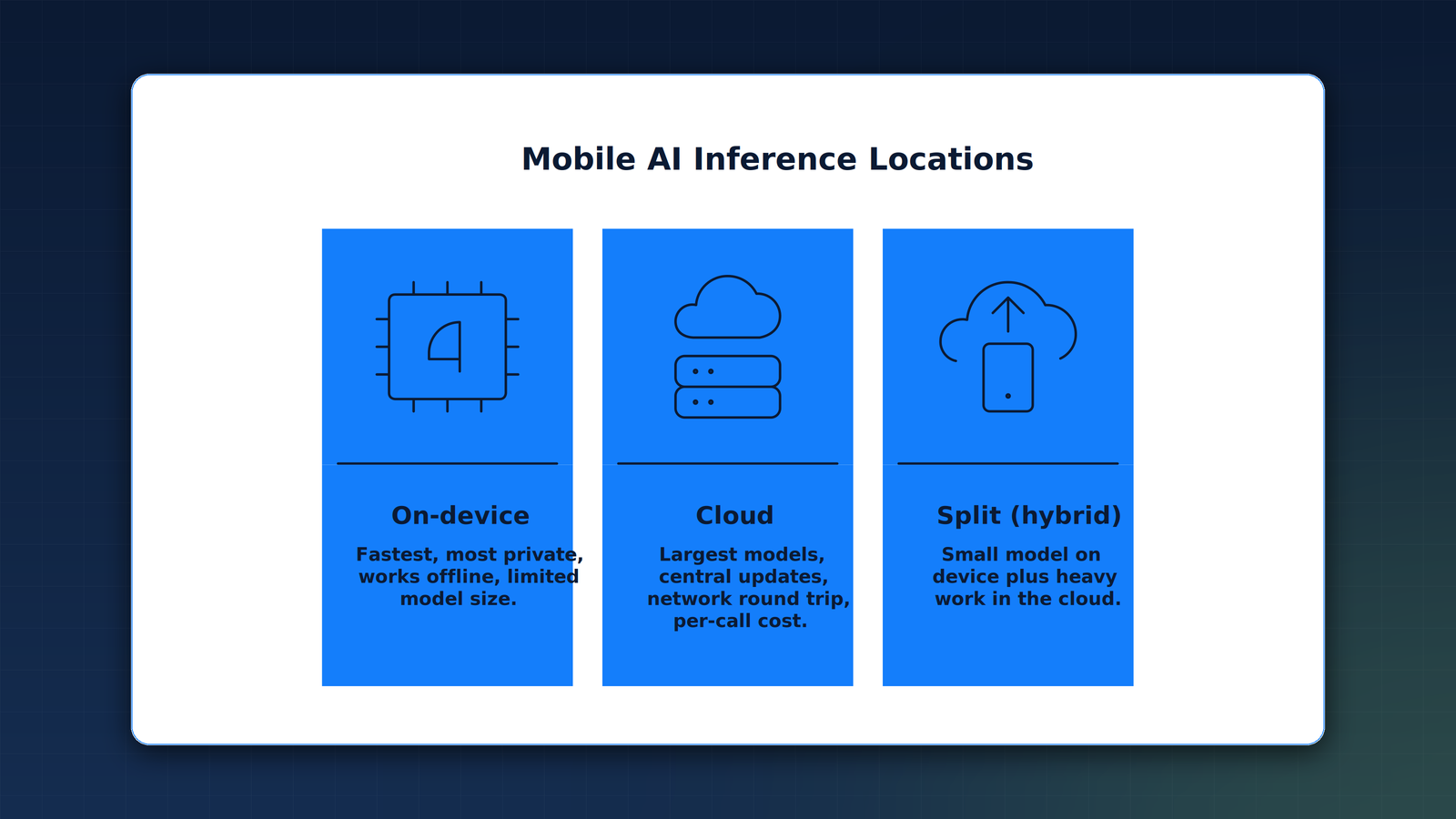
What do the three placements actually mean?
Beyond latency, a second pressure shapes the call: data residency, the requirement that certain data be processed and stored inside a specific legal jurisdiction. Weigh that and cost against the three places the model can live.
- On-device (edge): the fastest option and the most private, because the data never leaves the device, but bounded by the phone hardware and the model size it can hold.
- Cloud: supports the largest, most capable models and central updates, at the cost of a network round trip and a per-call bill.
- Split (hybrid) inference places a small, fast model on the device and routes the heavy or sensitive work to the cloud, so each request lands where it belongs.
Why does the "everything moves to the edge" story not hold?
The popular narrative says inference is migrating to the device, so build there and skip the cloud bill. The data complicates that. Deloitte forecasts that inference will account for roughly two-thirds of all AI compute in 2026, and that the market for inference-optimized chips will pass $50 billion. Crucially, Deloitte expects most of that inference to still run in data centers, on costly, power-intensive hardware, not on phones.
Despite expectations that inference would shift to the edge, Deloitte forecasts that most AI inference in 2026 will still happen in data centers, part of an AI chip market worth more than $200 billion.
The takeaway is not that on-device loses. It is that placement is a per-use-case engineering decision, not a default. A model small enough to run well on a phone is a different model from the one a data center serves. Choosing the device commits the product to the first; choosing the cloud commits it to a recurring bill that scales with every active user.
How should you weigh on-device AI mobile architecture against cloud?
Run the trade-study (a structured comparison that scores each option against weighted criteria) across five axes before committing headcount to any one path. For each feature in the app, score the placements rather than picking one architecture for the whole product.
- Latency: If the feature must respond in real time (camera effects, voice, typing assistance), on-device wins because it removes the network round trip. If a second of delay is acceptable, the cloud is fine.
- Data residency and compliance: If the data is regulated under GDPR or HIPAA, on-device keeps it on the phone and out of cross-border transfer questions. Cloud inference is workable, but only with region-pinned processing and the contracts to prove it.
- Cost and run-rate: On-device inference is paid once, at build time, and then runs free on the user hardware. Cloud inference is a recurring cost that grows with usage, which is exactly the run-rate Deloitte expects to dominate AI compute spend.
- Model size and capability: Frontier-grade reasoning does not fit on a phone today. If the feature needs the largest model, it needs the cloud.
- Offline behavior: If the app must work with no connection, the intelligence has to live on the device. If it can assume connectivity, the cloud is open.
In practice the answer for a serious product is rarely all of one. It is split inference: a compact model on the device for the fast, private, offline-capable path, and a cloud model for the heavy reasoning. We covered the server side of this in our piece on why your mobile app needs an AI backend in 2026.
What does this look like in a real build?
The placement call gets concrete fast once data sensitivity enters the picture. For an Indigenous nation we built a cross-platform enrollment platform for, the data architecture had to model matrilineal descent and govern sovereign-land records through custom GIS mapping. Sensitive community data of that kind pushes toward keeping processing close to the device and inside controlled boundaries, not shipping it to a general-purpose cloud endpoint by default. For an event-based dating app we built as a native cross-platform app, the compatibility logic favored fast, on-device responsiveness for the interactive parts, with heavier matching able to run server-side. Same question, different answer, because the latency and residency pressures differed by feature.
This is why we run the trade-study and prototype the split before a team commits. The cost of testing two placements on a real feature is small. The cost of discovering, after launch, that a cloud-only design fails a data-residency audit, or that an on-device-only design cannot hold the model the roadmap now needs, is a re-platform.
Key Takeaways
- The 2026 architecture decision is not whether to add AI to the app, it is where inference runs: on-device, cloud, or split.
- On-device wins on latency, privacy, offline support, and per-user cost; cloud wins on model size, capability, and central updates.
- The edge-only narrative is incomplete: Deloitte expects most inference to stay in data centers in 2026, so placement must be decided per use case.
- Score each feature across latency, data residency, run-rate, model size, and offline behavior rather than picking one architecture for the whole product.
- For most serious products the answer is split inference, validated with a prototype before headcount is committed.
Frequently Asked Questions
Is on-device AI always cheaper than cloud?
Over the life of the product it usually is, because on-device inference runs on hardware the user already paid for, while cloud inference bills per call and grows with every active user. The trade is capability: the cloud serves much larger models. For high-volume, latency-sensitive features, on-device often pays back; for occasional heavy reasoning, the cloud can be cheaper than shipping and maintaining a large on-device model.
Can we start in the cloud and move to the device later?
Sometimes, but it is rarely free. Moving a feature on-device usually means a different, smaller model and a rebuild of the inference path, so the migration is closer to a re-platform than a config change. That is the case for running the placement trade-study up front rather than deferring it.
What makes split inference hard to build?
The difficulty is the routing and the consistency: deciding per request whether it stays on the device or goes to the cloud, keeping the two models in agreement, and handling the handoff when connectivity drops. It is the strongest architecture for most enterprise apps and the one that most rewards prototyping before commitment.
Sources
- Gartner, "Gartner Predicts 40% of Enterprise Apps Will Feature Task-Specific AI Agents by 2026, Up from Less Than 5% in 2025," 2025. Link.
- Deloitte, "TMT Predictions 2026: More compute for AI, not less," 2025. Link.
Next Steps
Committing the AI architecture for a mobile product means deciding, per feature, where inference runs before the run-rate, the latency, and the compliance exposure are locked in. Stable Solutions runs the latency, compliance, and cost trade-study and prototypes the split-inference path so the call is validated, not guessed. Explore our App and Web Development work or contact our team to pressure-test the decision before you build.