
Why is the agent writing your code now a target?
The AI coding agent has moved from autocomplete to author, and that makes the build pipeline an attack surface in its own right. An AI coding agent is a system that reads a task, pulls in context from outside tools, and writes, runs, and commits code with little human review. In June 2026 the security firm Tenet Security disclosed a technique it named agentjacking, where an attacker hijacks a coding agent through the very tools it trusts and gets it to run malicious code on a developer machine. Tenet reported an 85% success rate across the most widely used agents, including Claude Code, Cursor, and Codex, and found at least 2,388 organizations exposed to the entry point it used. The deployed app was never the weak point. The pipeline that built it was. For leaders who authorized these agents across app teams, that reframes the question: you do not just need to secure the product, you need to govern the agent supply chain inside the build.
What is agentjacking, in plain terms?
Start with the mechanism. Prompt injection is an attack where text the model reads gets treated as a new instruction instead of as data, and indirect prompt injection is the version where that text arrives from an outside source the agent pulled in, not from the user typing. OWASP, the open standards body behind the widely used application security risk lists, ranks prompt injection as the number one risk in its Top 10 for LLM Applications for 2025. Agentjacking is indirect prompt injection aimed at coding agents through their tools.
In the disclosed attack, the agent read application errors through a Model Context Protocol server. Model Context Protocol, or MCP, is the open standard that lets an agent call outside tools and pull their data into its context, the working memory it reasons over. An attacker posted a fake error containing instructions formatted to look like normal remediation guidance. The agent could not tell a real crash from a planted one, treated the text as trusted, and ran it. Tenet calls this the Authorized Intent Chain, because nothing in the sequence is technically unauthorized: the agent had permission to read the tool, to run commands, and to touch the repository. The attack rides inside privileges you already granted, which is why, as Tenet noted, it slips past endpoint detection, firewalls, and network controls. There is nothing malicious to catch.
What does the agent actually expose?
The damage is not theoretical defacement. It is the secret store. A secret, or credential, is any value that proves identity or grants access: an API key, a deployment token, a database password. Coding agents run inside the environment where those secrets live so they can build and ship. Tenet documented one injected instruction reaching environment variables, AWS keys, GitHub tokens, git credentials, and private repository URLs, all with developer-level privileges. That is the software supply chain, the full set of code, tools, dependencies, and credentials that flow into a shipped product, compromised at the source. An attacker who reaches a deployment token does not need to breach production. The pipeline deploys for them.
This is the gap most authorization decisions skipped. Leaders approved the agents for the productivity gain and scoped review to the code they write. The tools the agents own, the context they ingest, and the secrets within reach were never brought under a control framework. Gartner predicts that 25% of all enterprise generative AI applications will experience at least five minor security incidents per year by 2028. The incident rate is becoming routine, and the pipeline is where many of those incidents will originate.
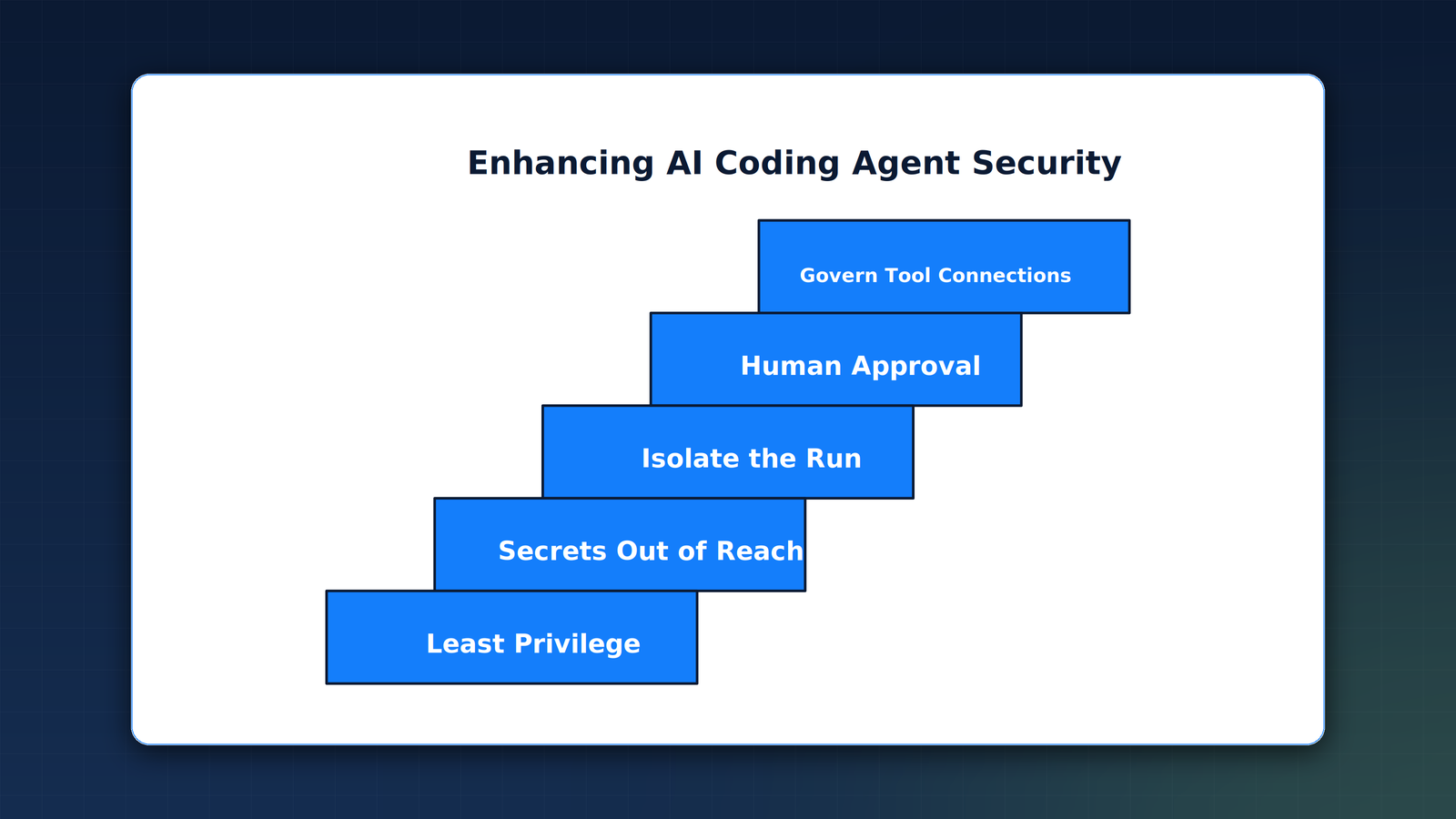
A framework for securing AI coding agents
Treat the agent as an untrusted execution path inside a trusted environment, and govern it the way you would any privileged service account. The controls below map to guidance OWASP and the agent vendors already publish. The Anthropic Claude Code security documentation reflects the same defense in depth posture: read-only by default, explicit approval for sensitive actions, and isolation for untrusted content.
- Least privilege for the agent. Scope each agent to the one project it works in, not the whole machine or organization. Least privilege means granting the minimum access required and nothing more. An agent that cannot read the production credential store cannot leak it.
- Put secrets out of reach. Production credentials belong in an approved secret store the agent cannot enumerate, not in environment variables or files in the working directory. If a secret does not sit where the agent can read it, an injected instruction cannot exfiltrate it.
- Isolate the run. Run the agent in a sandbox or virtual machine with filesystem and network limits, so a hijacked agent cannot reach internal systems or post data out. Keep any context fetched from outside tools separate from the instructions the agent follows.
- Human approval at the boundary. Require explicit human sign off before the agent runs a new command, installs a dependency, or pushes to a branch. Approval gates are the one control the disclosed attack could not route around.
- Govern the tool connections. Treat every MCP server and tool the agent can call as part of the attack surface. Allowlist the connections, check them into source control so they are reviewed, and assume any data they return can carry an instruction.
None of these are exotic. They are the controls a security team already applies to service accounts and third-party integrations, redirected at the agent. The work is deciding them deliberately for the pipeline rather than inheriting whatever defaults the agent shipped.
Why this belongs in the build, not bolted on after
Retrofitting these controls after an agent is embedded across app teams is expensive and political. The cleaner path is to set the agent privilege model, the secret handling, and the isolation boundaries when the pipeline is designed, so governance is part of how the app gets built. This is the secure by design principle the deployed app benefits from anyway, and it rhymes with the placement calls in on-device versus cloud AI for mobile: cheaper to get right at design time than to re-platform after a finding. Stable Solutions builds the agent governance and secret handling into the pipeline as part of the engagement, not as a checklist a team applies later.
Key Takeaways
- AI coding agents author production code, which makes the build pipeline an attack surface, not just the deployed app.
- Agentjacking is indirect prompt injection through the tools an agent trusts, reported at an 85% success rate and riding inside privileges you already granted.
- The real exposure is the secret store: a hijacked agent can reach cloud keys, deployment tokens, and repository credentials, compromising the software supply chain at the source.
- The governance framework is least privilege, secrets out of reach, isolation, human approval at the boundary, and reviewed tool connections.
- Build these controls in at pipeline-design time, because retrofitting them across embedded agents is far more costly.
Frequently Asked Questions
Is this a problem with one specific agent or tool?
No. The disclosed attack worked across Claude Code, Cursor, and Codex, and the entry point was a popular monitoring tool, not the agent itself. The root cause is structural: an agent cannot reliably tell trusted instructions from untrusted data arriving through a tool. The fix is a control framework around the pipeline, not switching vendors.
Do the agent built in safeguards solve this on their own?
They help and are necessary, but not sufficient alone. Read-only defaults and approval prompts reduce risk, yet the disclosed attack still ran code in most attempts. The vendor controls work best combined with least privilege, isolation, and secrets the agent cannot read, which is what a pipeline governance framework supplies.
Will human review of the generated code catch a hijacked agent?
Not reliably. Reviewing the code the agent commits does not see the commands it ran or the secrets it read during the build, which is where the damage happens. The control that matters is approval at the action boundary, before the agent runs or pushes.
Sources
- Tenet Security, "Agentjacking: Hijacking AI Coding Agents With Fake Sentry Errors," 2026. Link.
- The Hacker News, "Agentjacking Attack Tricks AI Coding Agents Into Running Malicious Code," 2026. Link.
- OWASP, "OWASP Top 10 for LLM Applications 2025," 2025. Link.
- Anthropic, "Claude Code Security," 2026. Link.
- Gartner, "Gartner Predicts 25% of All Enterprise GenAI Applications Will Experience At Least Five Minor Security Incidents Per Year By 2028," 2026. Link.
Next Steps
If your teams already run AI coding agents, the open question is who governs the tools, context, and secrets they touch inside the build. Stable Solutions ships secure by design app builds, embedding agent governance and secret handling controls into the pipeline as an R&D partner. Explore our App and Web Development work or contact our team to pressure-test the agent supply chain in your pipeline before it ships.