
Why is AI code debt a liability your board cannot see?
AI code debt is the technical debt that AI-assisted development creates, and it is structurally different from the ordinary kind because it passes review, accumulates silently, and stays invisible until it compounds into security and maintainability failures. Technical debt is the future cost of shortcuts taken in how software is built, the rework you owe later for moving fast now. AI-generated code is code written by an AI coding assistant rather than typed by a person. The ordinary version of this debt is visible: a developer knows they cut a corner and leaves a note. The AI version is not. The code looks idiomatic, it compiles, it passes the tests, and a reviewer waves it through. The shortcut is not in the syntax. It is in the understanding that was never built. Your board sees AI accelerating delivery. Your CTO is quietly inheriting a maintainability and security liability nobody has put a number on. This is a framework to measure it before it compounds.
What makes this debt different from ordinary tech debt?
Three properties separate AI code debt from the technical debt your teams already manage. Together they explain why the usual controls miss it.
First, it is cognitive, not just textual. Writing in InfoWorld in June 2026, Itamar Friedman named the core problem cognitive debt: the loss of understanding of how and why software was built the way it was. When a person writes a function, they reason through the edge cases and dependencies and carry that model in their head. When an AI writes it and a human approves it, the code exists but the understanding does not. You own software nobody on the team can fully explain, and that gap is the debt.
Second, it accumulates faster than anyone is watching. GitClear analyzed 211 million changed lines of code from 2020 through 2024 and found that copy-pasted code rose from 8.3% to 12.3% of changed lines, while refactoring, the disciplined rework that keeps a codebase healthy, fell from 25% of changed lines in 2021 to under 10% in 2024. The velocity that makes AI generation attractive is the same velocity that stops anyone from pausing to clean up. Duplication goes up, the cleanup that would offset it goes down, and the curve bends the wrong way.
Third, it converts into security risk, not just maintenance cost. The Software Improvement Group, a firm that benchmarks enterprise code health, published its State of Software 2026 on June 17 from an analysis of more than 30,000 enterprise systems. It found that AI-generated code carries roughly twice the security-risk violations of human-written code, and that 72% of AI systems in production score below its recommended build-quality rating. A maintainability problem that also doubles your security-risk surface is not a backlog item. It is a balance-sheet one.
How big is the liability, and why does it survive?
The unpriced part of this liability is the share that never gets cleaned up. A 2026 large-scale empirical study built a dataset of 302,600 verified AI-authored commits from 6,299 GitHub repositories across five widely used AI coding assistants. Using static analysis, an automated technique that inspects code for defects without running it, the researchers attributed each issue to the commit that created it and tracked whether it was ever fixed. The finding that matters for a balance sheet: 22.7% of the issues AI introduced still survived at the latest revision. Roughly one in four defects the assistant added was never paid down. That is the liability accruing in place.
It survives because the feedback loop that catches ordinary debt does not fire here. Code review, the practice of a second engineer reading a change before it merges, is calibrated to catch code that looks wrong. AI code looks right, and there is no author to ask why a tradeoff was made, because the author was a model and the reasoning was never recorded. This is the cognitive debt made concrete: the issue persists precisely because nobody ever understood the change well enough to question it. SIG also noted that productivity gains can disappear entirely once a codebase passes 100,000 lines, the point at which the model can no longer hold enough of the architecture in view to keep its own output coherent. The debt is largest exactly where the systems are most valuable.
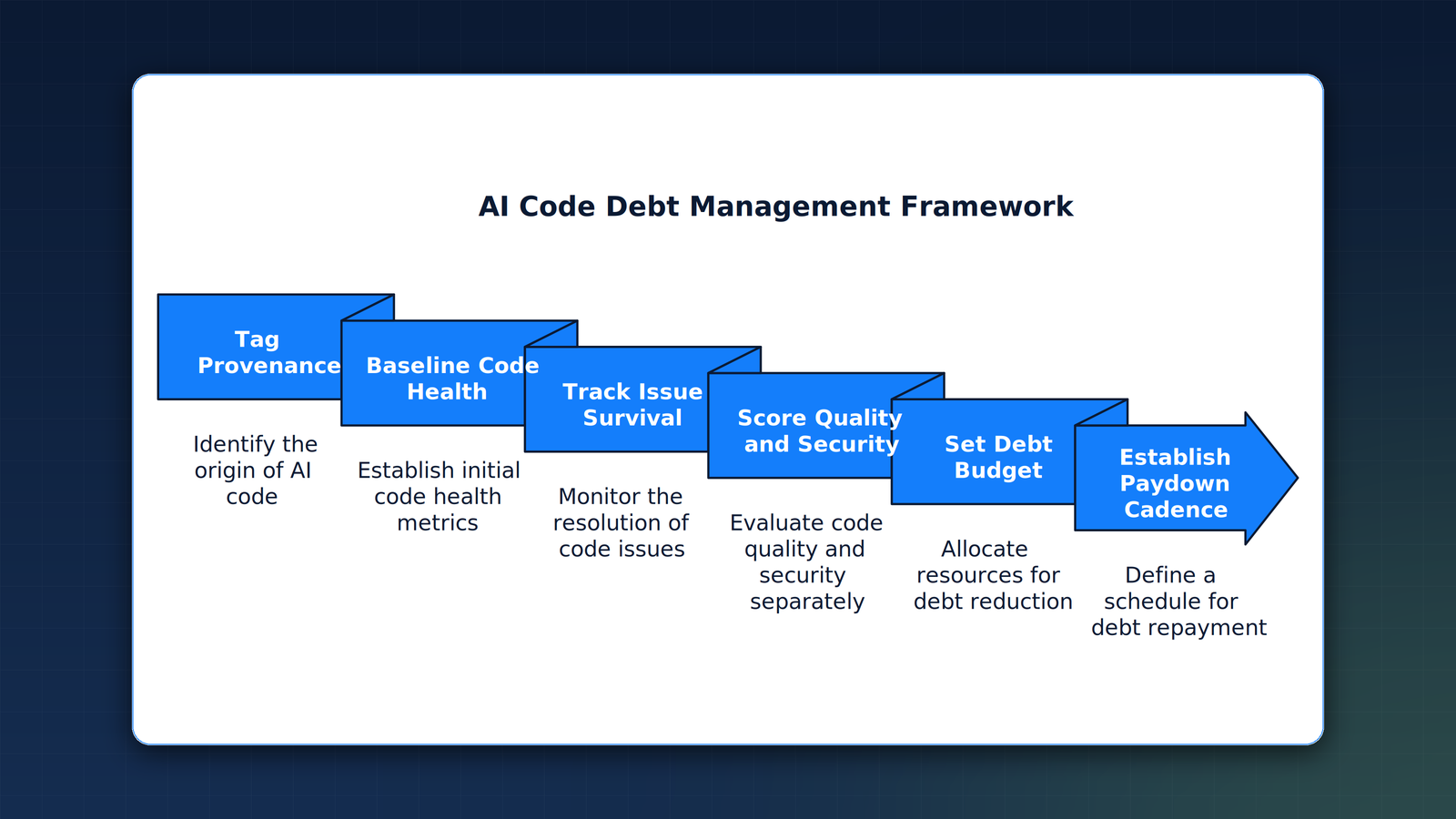
A framework to measure AI code debt before it compounds
You cannot manage what you do not measure, and right now most organizations are not measuring this at all. The first step is not to slow the AI down. It is to instrument it. The following framework turns an invisible liability into a tracked number, in the order a leadership team should adopt it.
- Tag the provenance. Record which code was AI-generated at commit time, so AI and human-authored code can be measured separately. You cannot price a liability you cannot isolate, and most pipelines blend the two.
- Baseline the code-health signals. Track duplication, code churn (lines rewritten shortly after they were added), and the refactoring ratio over time. A rising duplication curve and a falling refactoring ratio are the debt accruing.
- Run static analysis on every AI change, then track survival. Do not just count issues at merge. Track how long AI-introduced issues live, because the survival rate, not the introduction rate, is the real liability.
- Score build quality and security separately for AI code. Apply the same maintainability and security-risk benchmarks SIG applies, segmented by provenance, so the doubled security-risk surface shows up as its own line.
- Set a debt budget and a paydown cadence. Govern the number like any other liability: a ceiling the portfolio cannot exceed, and scheduled refactoring time to keep it under the line.
This is the same governance discipline that separates teams who get faster with AI from teams who get buried. SIG found that organizations with stronger controls around code quality and architecture can use AI to move faster, while those with weaker controls accumulate debt and security problems more quickly. The tool is identical. The instrumentation is what diverges.
Why this is an R&D problem, not a tooling purchase
Measuring AI code debt is not a dashboard you buy and forget. It is a research and measurement practice: defining the right code-health signals for your stack, instrumenting provenance and survival across the portfolio, and reading the curves before they bend. It is adjacent to the security governance an AI build pipeline already needs, covered in securing AI coding agents in the build pipeline, and it is the maintainability side of the equation we framed in the AI code rework tax. Stable Solutions instruments and quantifies AI code-health debt across the portfolio as the research-driven step before shipping more code, not as another tool that ships more of it.
Key Takeaways
- AI code debt is structurally different from ordinary technical debt: it passes review, accumulates silently, and converts into security risk, not just maintenance cost.
- The debt is cognitive, the loss of understanding of how and why software was built, which is why code review does not catch it.
- Industry data shows duplication rising, refactoring falling, AI code carrying roughly twice the security-risk violations, and about one in four AI-introduced issues surviving unfixed.
- The first step is measurement: tag provenance, track code-health signals and issue survival by provenance, then set a debt budget.
- Governance, not the choice of tool, separates teams that get faster with AI from teams that get buried.
Frequently Asked Questions
Is AI code debt just normal technical debt with a new name?
No. Ordinary technical debt is usually a known shortcut someone chose and can describe. AI code debt is the cost of code that looks correct, passes review, and ships, while the understanding behind it was never built. It is harder to detect and harder to unwind, and the data shows it correlates with a higher security-risk surface than human-written code.
Does this mean we should stop using AI coding assistants?
No. The productivity gains are real, and the data does not argue against using the tools. It argues for instrumenting them. The teams that pull ahead are the ones with the governance to measure the debt and keep it under a ceiling, not the ones that refuse the tool.
How do we even start measuring this?
Begin by tagging which code was AI-generated, so you can measure it separately. Then track duplication, churn, refactoring ratio, and how long static-analysis issues survive, segmented by provenance. The survival rate of introduced issues, not how many are introduced, is the number that maps to the liability.
Sources
- InfoWorld, "Why AI coding debt is different," by Itamar Friedman, 2026. Link.
- SecurityBrief UK, "AI coding tools raise debt and security risks, SIG warns," 2026. Link.
- GitClear, "AI Copilot Code Quality: 2025 Data Suggests 4x Growth in Code Clones," 2025. Link.
- arXiv, "Debt Behind the AI Boom: A Large-Scale Empirical Study of AI-Generated Code in the Wild," 2026. Link.
Next Steps
The question for your leadership team is whether anyone can put a number on the AI code debt your portfolio is accruing right now. Stable Solutions instruments and quantifies AI code-health debt across the portfolio as a research-driven R&D partner, so the liability becomes a tracked number before it compounds. Explore our App and Web Development work or contact our team to baseline the debt in your codebase before it shows up as a failure.